The internet takes a very serious position in our everyday lives. We do a lot of activities over the web, some of which we would like our privacy respected say like online purchases and some in which the matter of privacy isn't a bother, say like reading some news articles on the Daily Nation or New York Times.
Many people take to the assumption that due diligence is paid whenever privacy is called for. More often than not, that is never the case. There's a huge disparity and practical difference between how privacy is taken in our physical world and our digital world. Though let's not forget that with our current real time constant surveillance in our physical world, this disparity might not last for long, but then that's a story for another time.
Many people take to the assumption that due diligence is paid whenever privacy is called for. More often than not, that is never the case. There's a huge disparity and practical difference between how privacy is taken in our physical world and our digital world. Though let's not forget that with our current real time constant surveillance in our physical world, this disparity might not last for long, but then that's a story for another time.
Privacy on the web isn't usually as strong as it should be. There are technologies designed to compromise our very privacy.
People, other than technologies also play a part in privacy violation as is especially often the case with information leakage especially shared information. We sometimes wish we had complete and absolute control over what info is shared, sent or received in order to preserve our anonymity and privacy. Sadly this may not be the case.
All our activities on the web: the blogs we read, the online stores we frequent, our commonly used search keywords and the preference of videos we watch; all form info that is collected and used to profile us.
PROFILING
PROFILING: act/method of mapping user activities by time and logging preferences plus interests altogether, usually by tracking down user activity throughout the web, but due to caching and history preserving mechanisms built in the browsing agents, there are other methods as well.
About the profiles, honestly speaking, they are good for determining our content relevancy or creating customized services, and personalisation on the internet. However, we do end up suffering the causes of information determinism as well as direct marketing, i.e. targeted advertising and dynamic pricing. More on this in a while. A little more on information determinism; algorithms used by companies such as google, amazon, facebook ensure that our search results, articles or products are only related to our interests based entirely on our digital history. The very keystrokes we send out to the digital world determines our digital future. In essence, we will never get to see and view other people's opinions and interests. We all know how our digital worlds have a heavy impact on our physical world. My say, what a bad way to build a social planet.
Online shops and stores can use profiling to do market targeting where they'll present your favorite and desired products a little more expensive compared to the uninteresting stuff you don't care about, if only to make a little more profit from you. After all, if the product is something you'd die for, you'll eventually buy it notwithstanding the high price. It's also usually quite easy updating user profiles based on purchase statistics.
Advertising nowadays is done together with profiling by tracking user activity and storing info based on contextual and click-through bases. Advertiser's then are able to display proper adverts to the proper audience and in large numbers.
Data collectors/miners use special tracking techniques, often with help from service providers for profiling purposes to create accurate databases for merchandising and other activities.
About the profiles, honestly speaking, they are good for determining our content relevancy or creating customized services, and personalisation on the internet. However, we do end up suffering the causes of information determinism as well as direct marketing, i.e. targeted advertising and dynamic pricing. More on this in a while. A little more on information determinism; algorithms used by companies such as google, amazon, facebook ensure that our search results, articles or products are only related to our interests based entirely on our digital history. The very keystrokes we send out to the digital world determines our digital future. In essence, we will never get to see and view other people's opinions and interests. We all know how our digital worlds have a heavy impact on our physical world. My say, what a bad way to build a social planet.
Online shops and stores can use profiling to do market targeting where they'll present your favorite and desired products a little more expensive compared to the uninteresting stuff you don't care about, if only to make a little more profit from you. After all, if the product is something you'd die for, you'll eventually buy it notwithstanding the high price. It's also usually quite easy updating user profiles based on purchase statistics.
Advertising nowadays is done together with profiling by tracking user activity and storing info based on contextual and click-through bases. Advertiser's then are able to display proper adverts to the proper audience and in large numbers.
Data collectors/miners use special tracking techniques, often with help from service providers for profiling purposes to create accurate databases for merchandising and other activities.
SERVICE PROVIDERS: This will include Internet Service Providers and Web Service Providers.
Since user's traffic passes through service provider's proxies, their activities can be easily logged and even access denied by web service providers.
Since user's traffic passes through service provider's proxies, their activities can be easily logged and even access denied by web service providers.
 | |
| Know Your Logs |
Web service providers are usually the link between different participants by applying auditor services, placing third-parties adverts on their pages or could be collaborating with other web service providers for merging logs or creating wired networks for tracking purposes.
Collaborating websites can create comprehensive profiles by merging web activity logs and analyzing content: visited pages, downloaded files, followed links, click-through statistics of adverts e.t.c.. Statistics audit provider services might be behind these collaborations and are permanently tracking users, trading with the promise of personalized content and services in return.
The URL-referrer string carries previous URLs that the user visited before following a link. URL-referrers give info on: time of visit of referring site, content user visited and possibly the keywords used by the user in locating the site.
E-mail addresses can be attached to profiles by sending links or the URL of images in e-mail, embedding a special identifier into the URL referring to the recipients address. If the user opens the mail and decides to download the images or opens a link her IP address will be instantly revealed and by opening a URL in a browser the tracking identifier will be linked to the users e-mail address. Also, if a user registers for a malicious website’s service, registration information can be attached to the profile.
Besides the list of preferences, information about the user’s daily routine can be stored in profiles. The use of start pages in browser agents and subscribing to web feeds discloses such information and on the long run statistics reveal the outline of the user’s daily routine. Using browser agents for reading web feeds bears the threat of being tracked, since during the check-out session of a feed channel, cookies can be set and read. This also means automatic resolution of tracking identifiers to IP addresses at the first time of the day when the user starts the browser agent that checks out the web feed.
Privacy Violation: Anonymity Compromised
Below are three things which compromise our anonymity on the internet:
- IP Addresses
- User Agents
- Cookies
Normally, we usually share them and info they contain because they are used for customizing the web services we receive, for instance the display properties we share with websites helps the web content adjust to the screen size of the device we are using e.g. smart phones, a tablet or a large monitor. But this info can be used to create comprehensive profiles. Indeed whenever you are browsing or visiting the deep web or dark web, be advised to never maximize Tor browser to fit your maximum screen size instead use it in its default un-maximized size to improve your anonymity. From the user agent, info like the exact browser agent version, list of all installed plugins can be used to check existence of specific vulnerabilities which can be exploited to install spyware on user's computer.
In practice, anonymity needs to be guaranteed on two separate levels: Network and Application level. The communication framework, the OSI model, divides network traffic into several layers. Each layer is independent of the layers around it, and each builds on the services provided by the layer below while providing new services to the layer above. The abstraction between layers makes it easy to design elaborate and highly reliable protocol stacks, such as the ubiquitous TCP/IP stack. Different types of public info can be stored by network layers. Network and application level anonymity should be preserved in a different but related way.
In practice, anonymity needs to be guaranteed on two separate levels: Network and Application level. The communication framework, the OSI model, divides network traffic into several layers. Each layer is independent of the layers around it, and each builds on the services provided by the layer below while providing new services to the layer above. The abstraction between layers makes it easy to design elaborate and highly reliable protocol stacks, such as the ubiquitous TCP/IP stack. Different types of public info can be stored by network layers. Network and application level anonymity should be preserved in a different but related way.
 |
| TCP/IP stack model and information that can be used to compromise our privacy |
On these levels different types of information is leaking and also different types of active attacks have to be prevented and detected when securing the related layers.
IP ADDRESS:
Using and revealing our IP addresses is a technical need due to the workings and architecture of the internet. Their uniqueness allows for tracking pretty well. Geo-Location becomes a reality. Censorship activities are usually done by blocking IP addresses, domain names or filtering available content by keywords and patterns. Censorship will often include surveillance. The surveillance will involve tracking and identifying users sharing or accessing blocked content.
The downfalls of using IP addresses to track users however easy this is is that the IP may not necessarily denote a user, since IPs could also be referring to network devices or groups of users for instance due to use of NAT(Network Address Translation) techniques. In cyber cafe's several users will use a common computer which has only one IP.
In the transport and IP layer, port numbers and IP addresses have to be obscured. Using the Tor network, VPN's and proxies helps hide our real IPs quite well and are reliable enough against IP tracking. Web servers can no longer log in our real IPs us we have hidden behind proxy, VPN and Tor IPs and our traffic is routed to the private network. Learn more about this by reading my previous article on anonymity here. However there's still a better way of tracking users, in a way that users can be identified personally. This is browser-based tracking.
USER-AGENT:
Websites use a string called user-agent in order to identify unique users that log in to their sites. The user-agent provides useful info to web servers in order to provide a tailored HTML code to provide better user experienced. But the same info can be used to exploit the browser being used by the targeted users. For instance, user-agents can be used to detect users using Macbooks and thus in case of an online shop, products prices are made higher than normal. This is a case of dynamic pricing.
COOKIES:
Cookies are used to store a user's settings on the computer for web services enjoyed. This is done so by the browser agent sending all cookies belonging to a certain visited web site. A site will only access its own cookies. Cookies presented are used as unique identifiers to identify one as a repeat visitor whenever you visit the site again in future. Sometimes cookies only store session identifiers which refer to resources or database entries stores at the web service provider.
Cookies may also contain tracking identifiers also called third-party cookies. Since service providers can't read each others' cookies, they use web bugs or adverts placed on other's sites to detect users visiting a tracked website.
WEB BUGS: are small, transparent 1x1 pixel sided images hidden on pages, especially for creating statistics or for tracking purposes.
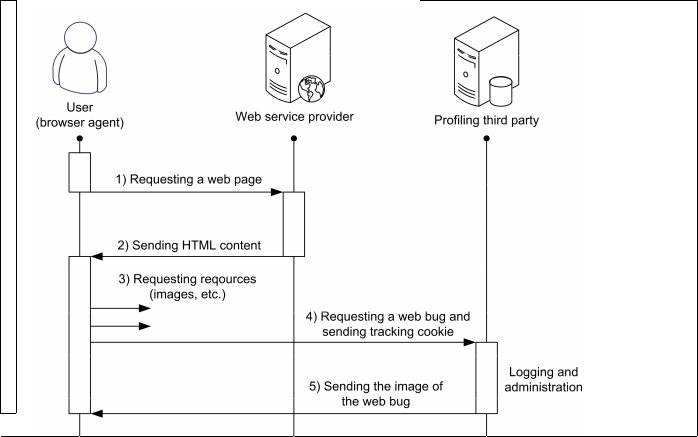 |
| How Web Bugs Work |
The visited website's content is downloaded in two steps:
- browser agent downloads the content descriptor file in HTML format
- it then downloads images and other resources marked in page's descriptor which might have downloaded from elsewhere, from a third party, setting the basic idea for web bugs.
Modern browser agents however usually do offer the possibility for privacy-aware users to manage, and hence delete cookies. Possibly this was the reason why Flash Persistent Identification Element (PIE) was introduced. PIE-s are based on a cookie-like client side storage element called Local Shared Object (LSO). These objects are harder to check and detect changes, and even to delete, however, tracking possibilities are limited, too. PIE elements are utilized with Flash advertisements accordingly to web bugs. Furthermore, there are alternative methods, like exploiting vulnerabilities in the browser agent’s cache mechanism to use script variables (like JavaScript) storing tracking identifiers among several websites.
To prevent websites from identifying you, always delete your cookies from your browser. For the programmer/hacker, Python comes with a built-in library called Cookielib that allows one to deal with cookies websites present you with. You can save them, see them and at the end of it all for anonymity, delete them.
Let's talk a little on spyware.
Spyware
Spyware generally collects info about a user, generates profiles and compiles a list of preferences based on analysis of off-line databases such as file cache's, URL history and cookie databases. For instance, using file caches, spyware can tell the exact content a user viewed and create a preference profile. Primarily, processing the file caches is used together with creating tracks by URL history and cookie databases.
Cookie and PIE databases can always be accessed without any restrictions off-line and on executing complex queries, spyware agents can link several tracking identifiers altogether sing data and text mining techniques, even from separate databases.
To protect oneself from spyware always take care of what you download. Check that they are not Trojans. Use SHA256 checksum and on a lesser tone MD5 hashes. Okay, just don't do MD5 hashes, please, you could mess yourself. Also limit information by browser agents.
Well, that's the end of my short treatise on anonymity, stay anonymous! Seriously do be anonymous, the digital world isn't one where you can manage being so overt that you are covert!
To prevent websites from identifying you, always delete your cookies from your browser. For the programmer/hacker, Python comes with a built-in library called Cookielib that allows one to deal with cookies websites present you with. You can save them, see them and at the end of it all for anonymity, delete them.
Let's talk a little on spyware.
Spyware
Spyware generally collects info about a user, generates profiles and compiles a list of preferences based on analysis of off-line databases such as file cache's, URL history and cookie databases. For instance, using file caches, spyware can tell the exact content a user viewed and create a preference profile. Primarily, processing the file caches is used together with creating tracks by URL history and cookie databases.
Cookie and PIE databases can always be accessed without any restrictions off-line and on executing complex queries, spyware agents can link several tracking identifiers altogether sing data and text mining techniques, even from separate databases.
To protect oneself from spyware always take care of what you download. Check that they are not Trojans. Use SHA256 checksum and on a lesser tone MD5 hashes. Okay, just don't do MD5 hashes, please, you could mess yourself. Also limit information by browser agents.
Well, that's the end of my short treatise on anonymity, stay anonymous! Seriously do be anonymous, the digital world isn't one where you can manage being so overt that you are covert!



No comments:
Post a Comment